Está claro que muchas personas estamos utilizando herramientas como ChatGPT o Claude para diversas tareas, ya sea para desarrollar un componente, clasificar un texto o crear contenido. Sin embargo, cuando hacemos una consulta, se desencadenan múltiples procesos, y no solo interviene el modelo de inteligencia artificial que utiliza la herramienta; también participan otros modelos y componentes de software.
En este contexto, el modelo puede apoyarse tanto en su propia información como en datos proporcionados por nosotros. Esta integración entre el modelo y fuentes de información externas se conoce como RAG (Retrieval-Augmented Generation).
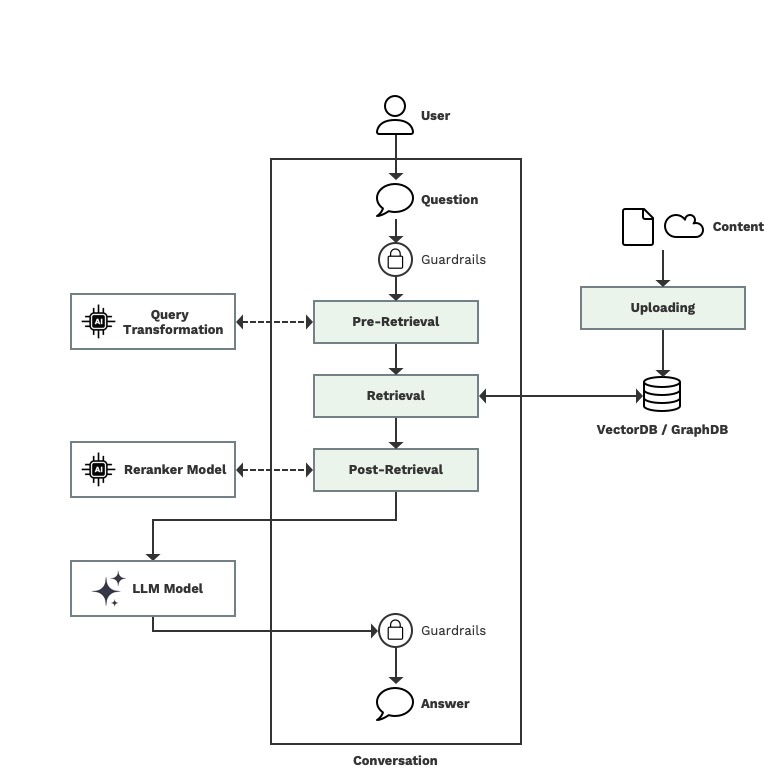
Fases de un RAG
Con acceso a modelos generativos avanzados o LLMs (Large Language Models) y una interfaz conversacional (Chat), un sistema RAG puede resumirse en tres fases principales: la fase de subida de contenido, la fase de recuperación y la fase de respuesta.
Fase de subida e indexación. Antes de preguntar.
Para que un modelo pueda responder correctamente, es necesario que haya sido previamente entrenado e incorporado conocimiento en este proceso, ya sea en forma de contenido multimedia o ejemplos de preguntas y respuestas estructurados como evidencias.
En este proceso de entrenamiento, la información propia del modelo ha sido clasificada y etiquetada previamente. Pero cuando queremos incorporar nuestra información, esta no siempre está bien organizada, bien sea porque son documentos no-estructurados o bien porque son documentos que incorporan imágenes y texto donde es difícil que de forma automática se extraiga el contenido con contexto (imágenes, textos, tablas).
Para poder subir un documento a nuestro repositorio propio de información, hemos de tener un proceso de extracción y carga lo suficientemente flexible como para poder procesar múltiples tipos de documentos, como PDF, TXT, CSV o urls. Existen componentes de software y servicios en la nube para procesar documentos y transformarlos en información que luego pueda utilizar el sistema de recuperación y el modelo para darnos una respuesta correcta. En este proceso, además, hemos de garantizar la seguridad y privacidad en el acceso a esta información.
Por lo general, la información que queremos es lo más simple, es decir, eliminar cualquier código o contenido que pueda generar ruido a la hora de poder recuperarlo. Esto es, limpiar el código HTML de una página web o eliminar el código de formato del documento. Lo que queremos es contenido informacional.
Después de limpiar el código
Cuando ya tenemos este código, podemos agregarle metainformación, como nombre del fichero, número de páginas, título del documento o incluso un resumen del documento para que nos permita localizarlo en el contexto de la conversación. Esta metainformación puede ser incorporada de forma manual o por el servicio de procesamiento, o utilizando modelos de inteligencia que resuman el contenido o que extraigan el título del documento.
Una vez tenemos el contenido y la metainformación, procederemos a guardarlo en un repositorio de datos. En Múltiplo, utilizamos exclusivamente vector databases, pero existen técnicas que implementan otras, como graph databases, o una combinación de tipos de bases de datos.
Para guardar el contenido, en el caso de las vector databases, primero hemos de crear los vectores de la información o vector embeddings. Existen componentes de software y múltiples servicios para crear estos embeddings. OpenAI, Cohere o A21, ofrecen esta funcionalidad en modo de modelos (embeddings models). La elección del modelo depende del tipo de vector database, la dimensión de los vectores y el dominio o ámbito de uso.
Estos vectores se generan dividiendo el contenido en fragmentos más pequeños, conocidos como chunks, y parametrizando tanto su tamaño (chunk size) como su superposición (overlapping) con los fragmentos previos y posteriores.
Con estos chunks listos, procedemos a almacenarlos como filas dentro de nuestra vector database.
Fase de recuperación o retrieval. Preguntando al modelo.
La fase de retrieval se divide en tres subfases: pre-retrieval, retrieval y post-retrieval.
Antes de detallar estas subfases, es importante comprender qué contenido utilizará el modelo para generar una respuesta. Esto incluye: el System Prompt (las instrucciones que definen el comportamiento del modelo), el User Prompt (la pregunta realizada por el usuario), el contexto de la conversación previa (memoria conversacional), y, finalmente, el contenido recuperado durante la fase de retrieval.
Es importante destacar que una correcta definición del System Prompt impacta directamente en la calidad de las respuestas, ya que establece el ámbito del contenido y el nivel de detalle que debe proporcionar el modelo.
Pre-retrieval
A partir de la pregunta del usuario, podemos utilizar varias técnicas para asegurar que la pregunta sea la correcta para que el modelo tenga la información relevante para una correcta respuesta. Con la pregunta, podemos utilizar una IA que la mejore, por ejemplo, reestructurándola y eliminando ruido. Esta técnica es denominada Query Rewriting. Esta IA también podría buscar si la pregunta ya ha sido respondida utilizando un sistema de caching y recuperando la respuesta ya ofrecida en otro momento. Esto, además, reduce el tiempo de respuesta y los costes del sistema. Otra posible técnica es la denominada MultiQuery Retrieval. Esta técnica consiste en que una IA, genere varias preguntas similares a la pregunta del usuario. Con estas preguntas, podríamos ampliar la búsqueda de información para que el modelo obtenga más contexto para procesar. Es similar al concepto de “Chain-of-Thought” que introdujo OpenAI con el modelo o1 (aunque este concepto ya se introdujo anteriormente por Google), aunque las instrucciones y el objetivo son diferentes.
En Múltiplo, utilizamos una segunda IA que permite reescribir la pregunta y utilizar un sistema de caching para ofrecer respuestas más rápidas al mismo tiempo que reducimos costes. Todavía no hemos explorado cómo se comportaría la técnica de MultiQuery Retrieval, aunque ya estamos refactorizando partes de nuestras soluciones para poder incorporar esta técnica.
Es importante incorporar un sistema de Guardrails o filtros para garantizar precisión, seguridad, y calidad en las respuestas. Su aplicación estratégica permite mitigar riesgos, mejorar la experiencia del usuario y alinear el sistema con los objetivos del proyecto. Este componente puede ser aplicado tanto antes de la fase de pre-retrieval como en la fase de post-retrieval. En Múltiplo utilizamos una combinación de filtros (Answer Filters) y las capacidades de Amazon Bedrock Guardrails, una solución independiente al modelo de inteligencia artificial.
Retrieval
Esta subfase se encarga de la búsqueda y recuperación de información que posteriormente va a utilizar el modelo para darnos una respuesta. En esta subfase, también podemos utilizar técnicas como HYDE (Hypothetical Document Embeddings), también conocida como Query2Doc, Generative Multi-hop Retrieval o Hybrid Search Exploration. A día de hoy, en Múltiplo, no hemos podido implementar estas técnicas y no podemos valorar el impacto. De todas formas, de entre estas técnicas, creemos que aplicar un modelo BM25 en combinación con la búsqueda de embeddings, puede resultar en una mejora considerable cuando el volumen de información es alto. Aplicar un modelo BM25 se engloban dentro de la técnica Hybrid Search Exploration.
Si únicamente utilizamos la búsqueda por embeddings en una vector database, entonces, es importante poder configurar el parámetro top_k. Este parámetro ajusta el número de resultados que nos va a devolver la vector database.
En Múltiplo utilizamos Pinecone como vector database, aunque hay otras plataformas como Qdrant o Vertex AI de Google.
Post-Retrieval
Una vez hemos obtenido los bloques de información de nuestro repositorio, podemos realizar varias acciones para verificar o cambiar la relevancia de los resultados. La mejor opción es utilizar los llamados modelos de ReRanking. Estos modelos reasignan puntuaciones de relevancia y reorganizan los documentos en un nuevo orden.
Existen diferentes tipos de modelos de reranking. En Múltiplo utilizamos los modelos de Cohere Reranker, definidos como modelos de evaluación semántica profunda y que permiten una longitud de contexto de 4096 tokens, permitiendo manejar documentos extensos y lingüísticamente complejos.
En conclusión
El dominio de la arquitectura de los sistemas RAG representa un valor añadido significativo en el desarrollo de asistentes inteligentes o chatbots asistidos por IA, ya que permite integrar capacidades avanzadas de recuperación de información con modelos generativos. Esta combinación no solo mejora la precisión y relevancia de las respuestas, sino que también optimiza la experiencia del usuario al ofrecer soluciones más completas, personalizadas y contextualmente adaptadas a las necesidades específicas de cada caso de uso.
